| Navigation | Datenbasis des integrierten Scorecardkonzeptes | |
| Startseite |
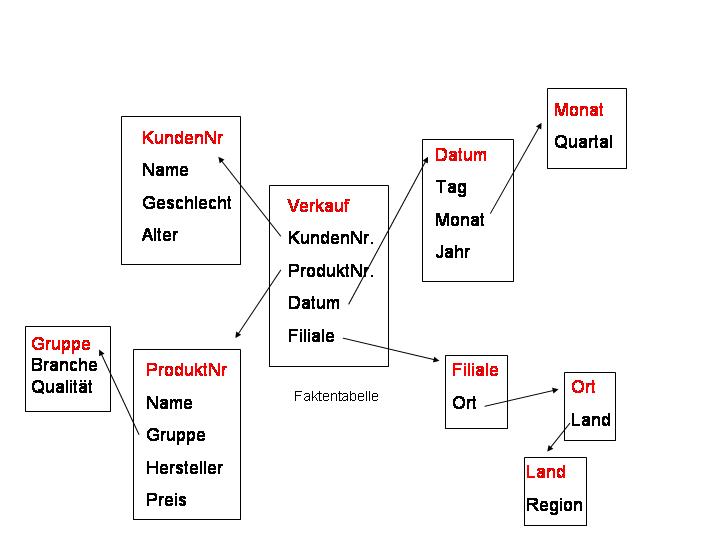
Kurzzusammenfassung: Das Scorecardkonzept selbst ist ein Instrument zur Informationsauswertung. Seine Leistungsfähig ist damit direkt von der zugrunde liegenden Datenbasis abhängig. Mit der Qualität der Datenbasis steigt und fällt unmittelbar die Aussagekraft der Scorecard. Ausgangssituation ist grds. immer ein heterogener Datenpool. D.h. in der Unternehmung befinden sich eine Vielzahl voneinander unabhängiger Datenquellen. Der Informationsgehalt dieser Datenquellen kann sich überschneiden und auch unterscheiden. Daten können mehrfach abgelegt und sich widersprechen. Zudem ist die Aktualität der Daten unterschiedlich. Eine ganzheitliche Auswertung auf Basis der Gesamtheit aller Informationsquellen ist daher unmöglich. Erforderlich ist ein homogener Datenpool hoher Datenqualität. In den Datenpool dürfen nur historisierte und bereinigte Daten eingelesen werden. Die Aktualität und Gültigkeit der Daten, wie auch deren Integrität und Konsistenz muss sicher gestellt sein. Diese Anforderungen erfüllt ein Datawarehouse Inhaltsübersicht: 1. Heterogener Datenpool / Problemstellung 3. Datawarehouse und Scorecard Das integrierte Scorecardkonzept benötigt Detailinformationen aus allen Teilen des Unternehmens sowie der Unternehmensumwelt. Diese Informationen müssen ständig in aktualisierter Form vorliegen, eine schnelle Reaktion auf Veränderungen, mithin Kernfunktion der Scorecard, ist sonst nicht möglich. Weiter ist die Qualität der mit Hilfe der Scorecard getroffenen Führungsentscheidungen nur so hoch wie die Qualität der Daten auf denen sie beruhen. Damit sind auch die übrigen Qualitätsanforderungen an Daten, wie Integrität, Konsistenz usw., von großer Bedeutung. Die Scorecard muss also auf ein Informationssystem aufbauen, das Informationen sammelt, aufbereitet und weiter leitet. Daraus ergeben sich folgende Fragen: - welche Daten sind vorhanden ? - wo befinden sich die Daten physisch ? - wie werden die Daten verwaltet bzw. verfügt das Unternehmen über ein globales Datenmodell ? - genügen die vorhandenen Daten den Anforderungen der Scorecard, inhaltlicher und qualitativer Art ? - lassen sich die Daten mit vertretbaren Aufwand erschließen, bzw. hat die Datenquelle langfristigen Bestand, wie hoch sind die Kosten der Datenerhebung ? 1. Heterogener Datenpool und ProblemstellungNachdem der konkrete Informationsbedarf geklärt ist müssen die Quelldatensysteme analysiert werden. Als Datenquelle für die Scorecard kommen verschiedene externe und interne Informationsquellen in betracht. An erster Stelle steht das betriebliche Rechnungswesen, jedes Unternehmen verfügt über diese Informationsquelle. Das Rechnungswesen liefert jedoch nur finanzorientierte Informationen, zudem sind Verzerrungen durch Bilanzierungsregeln u.dgl. nicht auszuschließen. Umfangreichere Informationen bietet die Kosten und Leistungsrechnung (KLR), resp. das Controlling. Diese Daten sind bereits den Anforderungen der Unternehmenssteuerung angepasst, d.h. sind unverfälscht und betreffen auch nichtfinanzielle Größen. Eine besonders genaue Beobachtung und Abbildung des Leistungserstellungsvorgangs ermöglicht die Prozesskostenrechnung. Die Prozesskostenrechnung ist die optimale Informationsgrundlage für die interne Perspektive. Gegenüber der KLR ermöglicht die Prozesskostenrechnung eine differenziertere Kostenaufschlüsselung und bewirkt dadurch die Offenlegung der tatsächlichen Leistungsanspruchnahme Auch kostenstellenübergreifende Kostentreiber können identifiziert werden , Ursache-Wirkungszusammenhänge können so exakt dargestellt werden. Diese Informationsquelle ist damit besonders für Unternehmen wichtig die individuelle Kundenwünsche erfüllen wollen. Die Folgen von Programmänderungen werden sofort exakt deutlich. Unter dem Gesichtspunkt der Zukunftsorientierung der Scorecard, der Schwerpunkt liegt darauf die Zukunft abschätzen zu können und nicht die Vergangenheit zu dokumentieren, ist auch das Target Costing von Interesse. Das Target Costing basiert auf der Vorgabe von Zielwerten. Diese analytisch ermittelten Zielwerte dürfen nicht überschritten werden wenn die Planvorgaben erfüllt werden sollen. Bei einer Kostenüberschreitung liefert das Target Costing so gezielte Informationen um die Kosten zu senken. Maßstab ist dabei immer die Marktsituation, d.h. Umweltinformationen. Ebenfalls prospektiv orientiert ist die konstruktionsbegleitende Kalkulation. Mit Hilfe der konstruktionsbegleitenden Kalkulation lassen sich schon in der Frühphase der Produktentwicklung Aussagen über die Kosten treffen. Alternativen können so frühzeitig berücksichtigt werden. Besonders schwierig ist es Daten über weiche Größen, wie z.B. Verhaltensweisen oder Meinungen zu finden. Im Zweifel müssen entsprechende Datenquellen erst erschlossen werden. In Betracht kommen Beobachtungen des menschlichen Verhaltens, entweder in natürlicher Umgebung oder in einer künstlich geschaffenen Umgebung. Es sind auch rein sprachliche Auswertungen möglich, z.B. durch Call Center. Eine weitere ergänzende Erhebungsmethode sind Fragebögen, entweder schriftlich oder auch webbasiert. Allen diesen Informationsquellen ist gemeinsam dass sie singulär, d.h. per se unabhängig voneinander, vorliegen. Diese Unabhängigkeit ist umfassend. Alle denkbaren Informationsquellen befinden sich im Zweifel auf unterschiedlichen Servern und werden von unterschiedlichen Abteilungen betreut. Das liegt daran, dass diese Informationsquellen ursprünglich für die Informationsbedürfnisse unterschiedlicher Abteilungen konzipiert sind. Ein globales Datenmodell kann damit nicht vorausgesetzt werden, es handelt sich i.d.R. um bereichsspezifische Datenbanken. Daraus ergeben sich folgenschwere Konsequenzen. Die Basisqualitätsanforderungen an Daten, d.h. Integrität, Konsistenz usw., ist nur innerhalb der spezifischen Datenbanken, aber nicht untereinander, gegeben. Zudem ist eine Datenanalyse in den operativen Systemen nicht unproblematisch. Die Datenmodelle in den operativen Systemen sind den speziellen Bedürfnissen der Fachabteilungen angepasst, d.h. applikationsorientiert, den speziellen Prozessen angepasst, und nicht themenorientiert, also funktionsbereichsübergreifend wie für eine ganzheitliche Auswertung erforderlich. Zusätzlich führen externe Abfragen zu einem erheblichen Performanceverlust der operativen Systeme bis hin zur völligen Blockade. Weiter enthalten die operativen Systeme selten historische Daten, bzw. historische Daten sind nicht vor Veränderungen geschützt. Eine Reproduzierbarkeit von Analysen ist so nicht gegeben. Eine Sammlung unabhängiger Datenbanken / Datenquellen ist aus diesen Gründen als Informationsgrundlage für die Scorecard ungeeignet. Erforderlich ist ein ganzheitliches integriertes Informationssystem, ein sog. Data Warehouse. 2. Lösung durch DataWarehouseDer Begriff Data Warehouse wurde von dem amerikanischen Unternehmensberater B.Inmon geprägt. Demnach ist ein ein Data Warehouse ein Informationssystem das durch zwei wesentliche Begriffe geprägt wird. Integrierte und historische Daten. Integriert bedeutet, dass das Data Warehouse aus einer Vielzahl interner wie externer Datenquellen gespeist wird. Dabei ist die Datenqualität besonders wichtig, aktuelle und fundierte Informationen sind die Grundvoraussetzung für tragfähige Entscheidung. Die historische Komponente lässt sich durch die Begriffe Time-Variant und Non-Volatile spezifizieren. Die Daten werden langfristig gespeichert, d.h. die Zeit ist eine wichtige Dimension bei der Datenspeicherung. Der zweite Punkt verfestigt diese „Ewigkeitsgarantie“; einmal gespeicherte Daten sind unveränderlich, es kann nur lesend aber nicht schreibend auf das Data Warehouse zugegriffen werden. („ nicht-volatil“). Darauf stützt sich das wichtigste Ziel des Data Warehouse Konzeptes: der „single point of truth“ der Datenwelt. Das Data Warehouse soll anstatt eines Datensumpfes eine quantitative Vertrauensbasis schaffen. Mittel dazu sind exakt dokumentierte und manipulationssichere Prüf und Bereinigungsprozesse. Die nähere Ausgestaltung ist in verschiedenen Formen möglich. a. ArchitekturErstes Variationsmerkmal ist die Architektur des Data Warehouse (DW) - einschichtige Architektur Bei der einschichtigen Architektur wird mit Hilfe der Auswertungswerkzeuge direkt auf die operativen Datenbestände zugegriffen. Dadurch wird gewissermaßen ein DW nur simuliert, denn das wichtigste DW Merkmal, die redundante Datenhaltung in einer eigenen DW Datenbank, fehlt. Dieses zentrale Merkmal, der Datenpool, ist maßgeblich für die Leistungsfähigkeit eines Data Warehouses verantwortlich. Durch die komplette Spiegelung der operativen Datenbestände in das Data Warehouse können diese Daten nicht nur bereinigt und aggregiert werden, sondern stehen auch unabhängig von laufenden Anwendungen in den operativen Systemen zur Verfügung. Auf Grundlage dieser „sauberen“ Datenbasis können beliebige Auswertungen gebildet werden ohne die operativen Systeme zu stören. Tatsächlich ist es nicht möglich gleichzeitig aus den operativen Datenbestände zu lesen UND zu schreiben. Erst durch die redundante Datenhaltung kann auf alle Daten frei zugegriffen werden und trotzdem bleibt die volle Funktionalität der operativen Systeme erhalten. Gerade dieser zentrale , redundante, Datenpool fehlt beim einschichtigen Modell. Als Grundlage für die Scorecard scheidet dieses Konzept so aus. - zweischichtige Architektur Beim zweischichtigen Modell setzt der DW Client direkt auf den Datenpool auf. Der DW Client führt so sämtliche Abfragen und Analysen selbst aus. Der Datenpool ist auf einen funktionsorientierten Auschnitt der operativen Datenbestände beschränkt. Beim zweischichtigen Modell handelt es sich daher auch noch um kein richtiges DW, man spricht von einem Data Mart. Für die Scorecard ist eine ganzheitliche Sicht notwendig. - dreischichtige Architektur Die dreischichtige Architektur gliedert sich in den DW Client, einen DW Server und der Data Warehouse Datenbank. Diese Architektur ist dafür ausgelegt die gesamten operativen Datenbestände zu integrieren und ist somit als Informationssystem für die Scorecard geeignet. b. DatenbankmodellDie Daten aus den operativen Systemen müssen in einer einheitlichen Form im zentralen Datenpool des DW abgelegt werden. Dazu dienen die ETL Werkzeuge. ETL steht für „Extraction Transformation and Load“, das ist der Vorgang mit dem die Daten aus den operativen Beständen herausgelöst, in das Datenmodell des DW übersetzt und in den Datenpool geladen werden. Zunächst ist zu klären in welchen Zeitabständen und in welcher Form die Daten aus den operativen Systemen herausgelöst, d.h. aktualisiert werden. Die Datenübernahme kann in festen zeitlichen Abständen stattfinden oder ausgelöst durch bestimmte Ereignisse. Es kann z.B. notwendig sein, dass bestimmte Transaktionen sofort in das DW übertragen werden oder aber die Übertragung wird automatisch ausgelöst sobald bestimmet Größen eine vorgegebene Veränderung erfahren haben. Die Daten können entweder komplett abgezogen werden oder aber man beschränkt sich auf die geänderten Daten. Diese Methode ist besonders bei Daten die nur selten eine Änderung erfahren effizient. Diese Änderung, d.h., Delta, deshalb auch „Delta Extraktion“, muss jedoch in zusätzlichen Feldern für das ETL Werkzeug signalisiert. Hieraus ergibt sich ein besonderer Aufwand. Die für die Scorecard relevanten Daten unterliegen jedoch typischerweise einem steten Wandel. Diese „Fluktuation“ kann sogar so hoch sein, dass die Daten zwischen den Extraktionszeitpunkten mehrfach interessante Veränderungen erfahren. Daher sollten die Daten komplett abgezogen werden und zusätzlich zwischenzeitliche Veränderungen in einer eigenen Logdatei gespeichert werden. Letztlich ist die Datenextraktionsstrategie aber an die technischen und finanziellen Möglichkeiten im Unternehmen gebunden. Wichtig ist in diesem Zusammenhang auch die Frage ob tatsächlich alle Daten aus den operativen Systemen benötigt werden d.h. welche Daten für das DW bzw. die Scorecard, relevant sind. Möglich ist auch, dass die zur Verfügung stehenden Datenquellen unzureichend sind und neue Datenquellen erschlossen werden müssen. Das Datenangebot ist mit dem Datenbedarf abzugleichen. Anschließend erfolgt die Übersetzung der operativen Daten in das Datenmodell des Data Warehouse. In den operativen System liegen die Daten i.d.R. in normalisierter Form vor. Für das Data Warehouse ist jedoch eine sog. OLAP-Datenbank erforderlich. OLAP steht für „Online Analytical Processing“. Die Bedeutung des Begriffs lässt sich mit der Abkürzung FASMI, d.h „fast Analysis of shared multidimensional Information“ umschreiben. Demnach geht es um eine schnelle, umfassende und mehrdimensionale Analyse aller Unternehmensdaten im Mehrbenutzerbetrieb. Der Schwerpunkt liegt dabei auf Merkmal „mehrdimensional“. Die Mehrdimensionalität wird versinnbildlicht durch einen (Hyper) Würfel dargestellt. Die Seitenflächen des Würfels sind die einzelnen Dimensionen, diese müssen keinesfalls auf sechs beschränkt sein, der „Würfel“ kann eine beliebige Anzahl an Seiten haben. Die Dimensionen entsprechen den operativen Sachzusammenhängen (Clustern) im Unternehmen, wie z.B. Zeit, Abteilungen, Produkte usw. Die Auswahl der einzelnen Dimensionen muss besonders sorgfältig geschehen, da von der Auswahl der einzelnen Dimensionen die späteren Abfragemöglichkeiten abhängen. Bei richtiger Wahl der Dimensionen erlaubt diese Technologie eine natürliche, funktionsbereichsübergreifende, d.h. themenorientierte Sicht auf die Daten und damit schnellere und komplexere Abfragen. Die Dimensionen stehen in einem festen Zusammenhang mit den Fakten, den einzelnen Kennzahlen. Fakten und Dimensionstabellen können unterschiedlich in der DW Datenbank organisiert sein. - Starschema Beim Starschema ist die Faktentabelle hochnormalisiert und steht im Mittelpunkt. Sie wird von den denormalisierten Dimensionstabellen umgeben. Die Dimensionstabelle „Zeit“ enthält so z.B. die Ausprägungen „Tag“, „Monat“, „Jahr“ usw. Daraus ergibt sich, dass jeder Primärschlüssel der Dimensionstabelle ein Fremdschlüssel der Faktentabelle ist. Diese Primärschlüssel müssen in den Faktentabellen zusätzlich abgelegt werden. Daraus lässt sich dann ein OLAP Würfel bilden der eine Kennzahl, resp. das Fakt, z.B. „Umsatz“, über verschieden Dimensionen, zB. „Zeit“, Abteilung“, oder „Produkt“, abbildet. - Snowflake-Schema Im Gegensatz zum Starschema sind beim Snowflake-Schema die Dimensionstabellen weiter normalisiert. Es existieren zusätzlich sog. LookUp Tabellen. Diese LookUp Tabellen enthalten eine weitere Detaillierung der Dimensionstabellen. Dadurch sollen Redundanzen reduziert werden, dadurch sinkt auch der Speicherplatzbedarf. Dieses Vorgehen ist dann sinnvoll wenn die Dimensionstabellen heterogene Objekte enthalten. Insbesondere die Bildung von Aggregaten wird dann optimal unterstützt. Allerdings steigt auch der Aufwand bei der Wartung und Befehlsgenerierung durch eine größere Anzahl an DW Tabellen.
Snowflake Schema Die normalisierten Dimensionstabellen (LookUp Tabellen) sind wie in einem Schneeflockenkristall um die Faktentabelle gruppiert
Für das Scorecard Konzept bedeutet dies, dass eine Kombination des Star und des Snowflake- Schemas zur Anwendung kommen muss. Aufgrund möglicher Redundanzen in den Dimensionstabellen ist bei alleiniger Verwendung des Star Schemas die für die Scorecard erforderliche Abfragesicherheit nicht gegeben. Optimal ist daher eine Kombination mit dem Snowflake-Schema in den Bereichen in denen heterogene Attribute vorliegen. Beim laden der Daten müssen zwei Dinge geschehen: (1) Historisierung der Daten Beim historisieren werden die Daten mit einem Zeitstempel versehen der das Alter, die Gültigkeitsdauer, u.dgl. der Daten nachweist. (2) Bereinigen der Daten. Um die Konsistenz der Daten sicher zu stellen müssen die Daten beim Laden einer Plausibilitätssprüfung unterzogen, d.h. bereinigt werden. Dazu gehören auch bestimmte Richtlinien die Datenqualität betreffend. Es muss geklärt sein in welchen Fällen Daten ganz abgewiesen werden oder aber wie mit offensichtlichen Fehlern und Ungenauigkeiten umgegangen wird. Das ist der Fall wenn z.B. im Feld „Geschlecht“ unbekannte, bzw. andere als m/w, Werte eingegeben sind. Ein weiteres Problem sind unterschiedliche Datentypen, das Datum kann z.B. als Text gespeichert sein. Zeichenketten müssen vereinheitlicht werden, Kundennamen etwa können mit unterschiedlicher Schreibweise erfasst sein, so dass die Gefahr der Mehrfachspeicherung besteht. Schließlich können während der Bereinigung bereits erste Aggregierungen stattfinden. Werden z.B. bei bestimmten Größen nur tägliche Änderungen, etwa Tagesumsätze, benötigt so sollten auch nur die auf diesen Zeitraum kumulierten werden, also Tagesumsätze, in das DW übernommen werden. Ähnliches gilt für erste Berechnungen. Wenn für die Scorecard z.B. nur die Größe „Zeitdauer“ benötigt wird, dann kann sie bereits im Rahmen der Datenbereinigung aus Anfangs- und Endzeiten berechnet werden. Diese Regeln, Art und Datum der Prüfungen müssen genauso wie die allgemeinen Zeitstempel in sog. Schattentabellen dokumentiert werden. Weiter müssen die Verknüpfungsschlüssel für neu hinzukommende und geänderte Dimensionsdaten im Metadata Repository angepasst bzw. hinterlegt werden. Die in den operativen Systemen verwendeten Schlüssel sind in den wenigstens Fällen einheitlich. Die Meta Daten sind die Daten über die Daten, d.h., die Datenbeschreibung. In Form eines Informationskataloges. Der Funktionsumfang eines solchen Informationskatalogs ist umfassend, er enthält auch diverse DV-technische und betriebswirtschaftliche Informationen. Beispielsweise werden durch Metadaten beschrieben: Die Herkunft der Daten Die Zusammensetzung der Daten Die Regeln für die Transformation der Daten aus den Quelldatenbeständen Die Verdichtungsstufen Die Version des DW Diese Datenbeschreibung trägt zusätzlich zur Datenqualität bei indem das Vertrauen in die Daten, die Verlässlichkeit der Daten, unterstützt wird.
DW Architektur 3. Das DW und die ScorecardDas DW stellt die Daten in einer niedrig aggregierten, ganzheitlich-unternehmensweiten und themenorientierten Form zur Verfügung. Damit ist das DW die optimale Informationsbasis für das integrierte Scorecard Konzept. Copyright © 2004 Oliver Oschmann. Alle Rechte vorbehalten.
|
|
|---|---|---|
| Ausgangssituation Anforderungen an Informationssysteme | ||
| Intergriertes Scorecardkonzept (Grundlagen) | ||
| Datenbasis | ||
| praktische Ausführung | ||